要約
近年では、特徴量自体もmanualではなく、機械学習手法で作成されることが主流になってきている。
LinkedInにおいて、embedding feature platformとして使われているPensieveについて紹介する。Pensieveは教師あり機械学習として学習され、潜在表現を利用したランクモデルに使われる。Talent solution・Careerで利用されている。
Introduction
LinkedIn Talent solution and career teamの目標は、仕事を探している人にマッチするpostを見つけさせることである。
我々は、embedding featureの計算に時間がかかることを解決するために、Pensieveというembedding feature platformを導入した。
Pensieve platform
1. Offline training pipeline
特徴量を作成する(MLは使わない?)。
2. Pensieve modeling
1の特徴量から、低次元のembedding表現を出力するモデルをtrainingする。
3. Embedding serving framework
学習済みのモデルをembedding servingとして提供する。

Pensieve model
model input
LinkedIn knowledge gparhがInputに用いられる。TItle, skill, company, geolocations, resumeなどがsparse categorical featuresとして利用される。
weighted bipartite graphにおいて、u(user), v(job), e(co-occurrence)を使う。
network architecture
Pensieve modelはDeep structured semantic modelにinspireされたDNNである。
member embedding、job embeddingを利用して、eを学習させる。
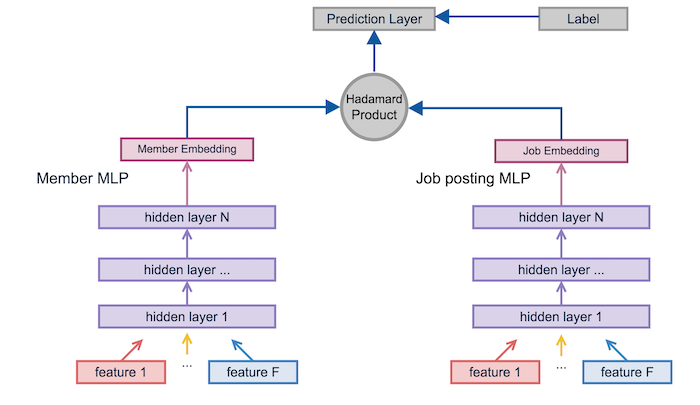
MLPにおいて、前の層で使った特徴量を使うことで性能を上げている(skip connection)。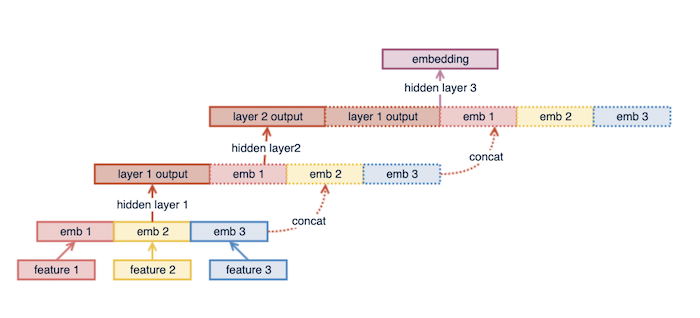
model deployment
学習が終わったら、member側のモデル、job側のモデルとして、それぞれdeployされる。
Nearline embedding serving framework
system architecture
効率的に出力できることと、実験を高速に回すことを意識して設計されている。
Apache BeamとSamzaを使っている。
job postingが作成・更新されると、Beam pipelineが動いて、modelが特徴量を生成して、Key value storeとKafka topicにpublishされる。
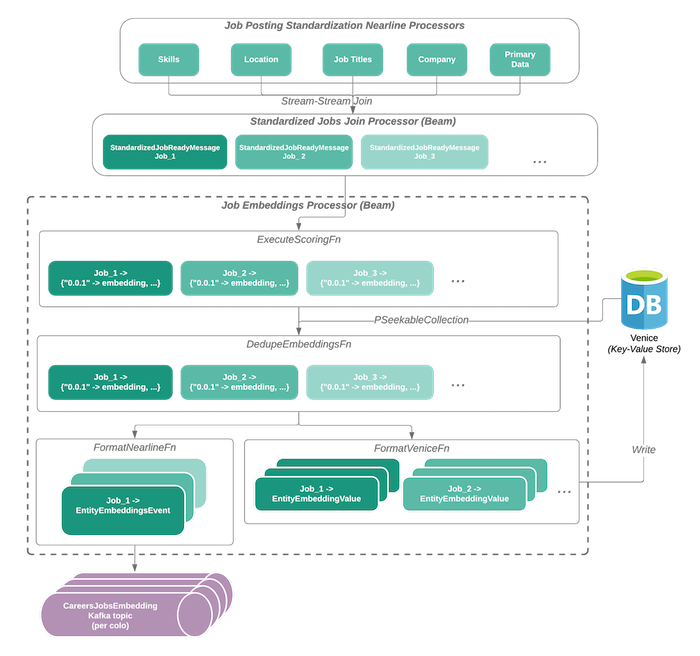
system optimization
heap sizeを増やしたり、並列処理数を増やすことで対応している。
multi-data-center strategy
計算を全データセンターで行うことで単一障害点となることを防ぐ。
